
tg-me.com/knowledge_accumulator/190
Last Update:
Почему интересен ARC prize?
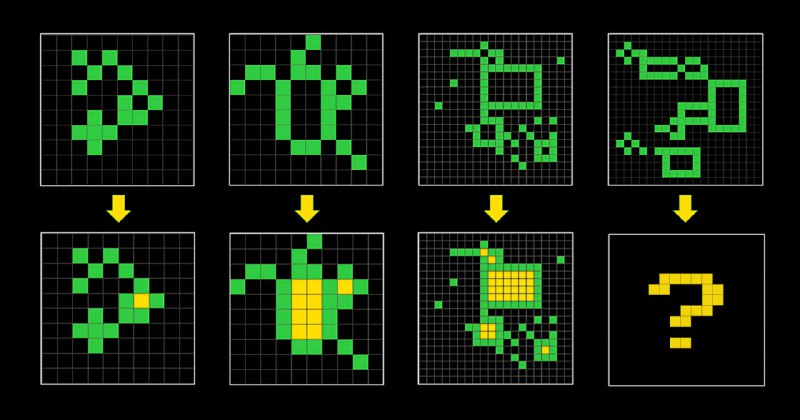
Для тех, кто пропустил - неделю назад был запущен конкурс на миллион, в котором нужно решить ARC - простейший "тест на IQ" для человека/алгоритма. В нём нужно по паре-тройке примеров увидеть закономерность и применить её на тестовом образце (см. пример задачи на картинке). Это проверяет алгоритм на обучаемость, а не на запоминание данных из интернета.
Как я уже недавно писал, если в лоб дать такие задачи GPT-4, то она работает достаточно стрёмно. В то же время, лидируют подходы на основе перебора всевозможных последовательностей элементарных операций. Нужно задать набор таких операций, например, из 50 штук, создать 50^4 "программ" и прогнать их на тренировочных образцах, применив успешные к тесту.
Больше года назад, как только я начал вести этот канал, я писал о том, что совместная работа перебора и нейросетей - это очень мощный инструмент. Это жжёт в Go, в математике, в приложениях. Поиску нужен качественный гайд, чтобы тащить, и таким гайдом вполне может быть LLM, как мы увидели на примере FunSearch.
Такой подход применим при решении "NP-задач", для которых мы можем быстро проверить кандидата на решение. Наличие только пары примеров в ARC сильно усложняет проблему, так как "оптимизация" программы будет работать плохо и нам легче на них "переобучиться" программой. Тем не менее, нет сомнений, что скачка в качестве достичь удастся, и такие попытки уже делаются. Осталось только дождаться сабмитов таких подходов в настоящий тест.
Тем не менее, есть проблема применимости такого подхода. Далеко не всегда в реальности мы можем генерировать тысячи/миллионы вариантов с помощью большой модели, применяя поверх какую-то проверялку, потому что быстрой проверялки просто нет. Для применимости этой большой модели в лоб к произвольной задаче нам нужно получить такую, которая как минимум решит ARC без помощи дополнительного перебора.
А зачем именно нужна такая модель? 2 простых юзкейса:
1) Хочется иногда с чашечкой латте провести время за глубокой дискуссией с моделькой, знающей и хорошо понимающей информацию из интернета. Если вы пробовали долго общаться с моделькой типа GPT-4 на сложную тему, вы замечали, что она вообще не вдупляет.
2) Запустить цикл технологической сингулярности
Про второе поговорим позже на этой неделе.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/190